In this guide, we will create and use table partitions in BigQuery. If correctly set up, a BigQuery table partition reduces query costs and runtime. Partitions can also reduce storage costs by using long-term storage for a BigQuery partition.
We can think of table partitions as a way of storing our clothes in the cabinet.
With an organized cabinet, you don’t need to open your entire cabinet to find what you’re looking for.
The same goes for partitioned tables in BigQuery. If you know which partition(s) to scan to find specific information, you get faster and cheaper queries.
What is a BigQuery Table Partition?
In BigQuery, we can split a single table into different sectors, or table partitions.
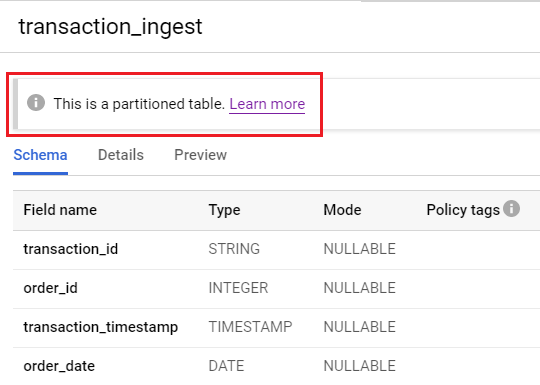
Partitioning a table does not split the table into several smaller tables. It all happens under the hood, but you can see the effect queries that process fewer data and take less time to execute.
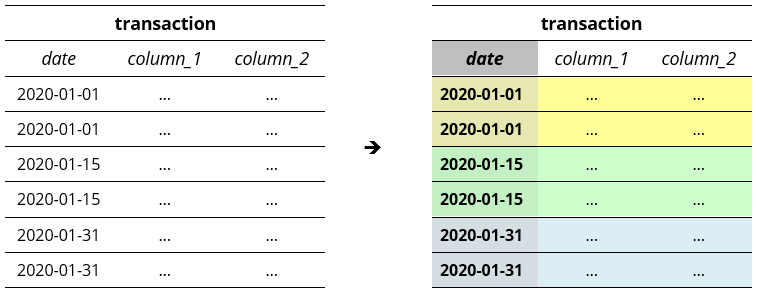
After creating a table partition on the date column, the table is now divided into partitions based on the date.
As an example, if we get the transactions made in 2020-01-01, BigQuery does not scan the entire table, only the partition in yellow.
Why You Need to Use Partitions in BigQuery
BigQuery is a scalable platform. You can start with the free tier, and as your business grows, the platform grows with you.
Reduced query costs when using partitions. When we deal with very large datasets, a partition can cut down the costs of a query.
Reduced storage costs. BigQuery has two classifications for storing data: active storage, and long-term storage. Long-term storage is calculated separately for each partition.
This means that old data will be charged for half the price after 90 days, even if they’re in the same table.
How to Create a Partitioned Table
You can create a partitioned table using BigQuery DDL, or the BigQuery Console Web UI.
You can also use the command-line tool bq, the BigQuery API, or schedule a job, but we will not cover them in this guide.
Here, we create a table named transactions.
BigQuery DDL
Add the PARTITION BY clause, depending on the type of partition.
CREATE TABLE `<dataset-name>.transaction` ( transaction_id STRING, order_id INT64, transaction_timestamp TIMESTAMP, order_date DATE ) PARTITION BY _PARTITIONDATE
BigQuery Console Web UI
You can enable partitioning by choosing a partition type in the table creation window.
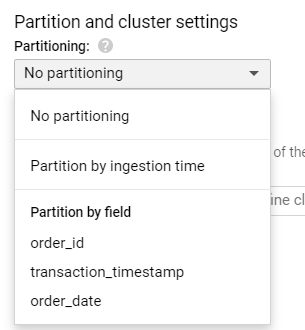
Tip: If you cannot see other partitioning options, only Partition by ingestion time, you may need to uncheck Auto-detect schema, and manually add your schema first.
How Do I Choose the PARTITION BY Field?
The general rule is to partition on the lowest granularity of your reports or business requirements.
If you need to prepare transaction reports per day, then you should partition by the transaction date.
In technical terms, first consider partitioning on a column that you use most often in the WHERE clause.
Partitioning vs Clustering vs Sharding – What’s the Difference?
With the latest changes in BigQuery, table sharding is no longer recommended. Thus, we are left with partitioning and clustering.
You can set at most one (1) partitioning type per table, and at most four (4) clustering types per table.
A table can have a partition and multiple clusters at the same time.
Table Sharding
We can still see table sharding on older datasets. These datasets have tables with the same name, plus changing date suffixes (YYYYMMDD).
For example, a public sample dataset of Google Analytics has date-sharded tables ga_sessions_*.
`bigquery-public-data.google_analytics_sample.ga_sessions_20170701` `bigquery-public-data.google_analytics_sample.ga_sessions_20170702` `bigquery-public-data.google_analytics_sample.ga_sessions_20170703` ...
When querying a date-sharded table, you only include the table(s) that you need. You can use either a UNION ALL, or a wildcard table format.
Using a BigQuery wildcard table to get data from January 1 to 14:
SELECT * FROM `bigquery-public-data.google_analytics_sample.ga_sessions_201707*` WHERE _TABLE_SUFFIX BETWEEN '01' AND '14'
The Google documentation suggests using partitioning over sharding for new tables.
Table Partitioning
We can partition a table based on a date, by the hour, or integers with a fixed range. As of writing, we can only choose one (1) partition among all of these partitioning types.
This means that if we partition by the order_date, we cannot partition it on another column.
We can also partition on the HOUR or DAY component of a timestamp column.
PARTITION BY TIMESTAMP_TRUNC(<timestamp_column>, HOUR) PARTITION BY TIMESTAMP_TRUNC(<timestamp_column>, DAY)
Table Clustering
When we cluster a table by a column (or multiple columns), BigQuery rearranges the table and moves similar records next to each other.
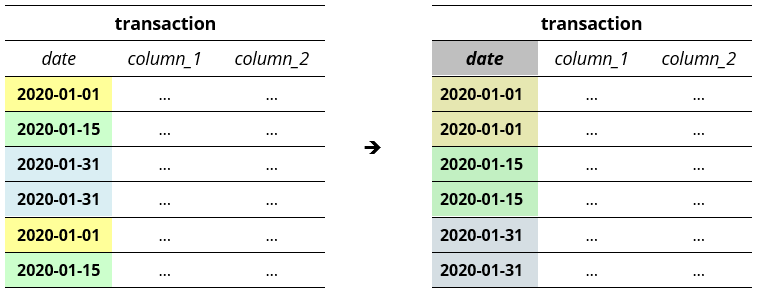
Similar to partitioning, table clustering also reduces query costs and runtime.
BigQuery supports table clustering for up to four (4) columns. We can also cluster using a text column, which is not supported in partitioning.
What are the Different Types of BigQuery Partitions?
We can partition a table in several ways:
- Ingestion Time, or Load Time. Data uploaded yesterday will be separate for the data uploaded today, tomorrow, and so on.
- Date or Timestamp. We separate records based on a
DATEorTIMESTAMPcolumn. - Integer. We can also separate records based on an
INTEGERcolumn.
Here’s a list of sample queries to create each type of partition.
CREATE TABLE `<dataset-name>.transaction` ( transaction_id STRING, order_id INT64, transaction_timestamp TIMESTAMP, order_date DATE ) PARTITION BY _PARTITIONDATE
CREATE TABLE `<dataset-name>.transaction` ( transaction_id STRING, order_id INT64, transaction_timestamp TIMESTAMP, order_date DATE ) PARTITION BY order_date
CREATE TABLE `<dataset-name>.transaction` ( transaction_id STRING, order_id INT64, transaction_timestamp TIMESTAMP, order_date DATE ) PARTITION BY order_date
CREATE TABLE `<dataset-name>.transaction` ( transaction_id STRING, order_id INT64, transaction_timestamp TIMESTAMP, order_date DATE ) PARTITION BY TIMESTAMP_TRUNC(transaction_timestamp, DAY)
CREATE TABLE `<dataset-name>.transaction` ( transaction_id STRING, order_id INT64, transaction_timestamp TIMESTAMP, order_date DATE ) PARTITION BY TIMESTAMP_TRUNC(transaction_timestamp, HOUR)
CREATE TABLE `<dataset-name>.transaction` ( transaction_id STRING, order_id INT64, transaction_timestamp TIMESTAMP, order_date DATE ) PARTITION BY RANGE_BUCKET(order_id, GENERATE_ARRAY(0,999,10))
What is Ingestion Time?
Sometimes, tables do not have a date or timestamp column. We can partition the table depending on the date or time that we inserted the records into BigQuery.
This can be used on data that are consolidated and uploaded at the end of the day.
How to Use the RANGE_BUCKET Partition
To create an integer partition in BigQuery, we need to know the beginning and end of our partitions, as well as the length within each interval.
Syntax for RANGE_BUCKET
RANGE_BUCKET ( <integer_column>, GENERATE_ARRAY(<beginning>, <end + 1>, <interval_length>) )
Let’s say we want to make the following partitions:
- 1st Partition: 0 ~ 999
- 2nd Partition: 1,000 ~ 1,999
- 3rd Partition: 2,000 ~ 2,999
- … and so on, until 99,999
Each partition has an interval length of 1000, since 0 to 999 contains 1,000 numbers.
The beginning is 0, and the ending is 99999. We now have the following partition clause:
PARTITION BY RANGE_BUCKET(order_id, GENERATE_ARRAY(0,100000,1000))
Important: Always add +1 to the end parameter.
While the beginning is inclusive, the ending is exclusive (or not included).
BigQuery Error When Creating a Partitioned Table
If you are trying to create a table using an invalid partition method, you may encounter this error message in BigQuery:
PARTITION BY expression must be _PARTITIONDATE, DATE(_PARTITIONTIME), DATE(<timestamp_column>), a DATE column, TIMESTAMP_TRUNC(<timestamp_column>, DAY/HOUR), or RANGE_BUCKET(<int64_column>, GENERATE_ARRAY(<int64_value>, <int64_value>, <int64_value>))
Possible Causes of Error:
- You may be using a timestamp column as-is. Solution: Use a
TIMESTAMP_TRUNCorDATEfunction (see examples above). - This error can also be encountered if you use
PARTITION BY _PARTITIONTIMEfor ingestion-date partitioning. Solution: UsePARTITION BY _PARTITIONDATEorPARTITION BY DATE(_PARTITIONTIME)instead. - The integer-range partition may have an incorrect format. Solution: Use a valid
RANGE_BUCKETformat (see examples above).
How to Create a Partitioned Table from a Query
We can also create a table partition from a SELECT clause.
CREATE TABLE `<dataset-name>.transaction_select` PARTITION BY order_date AS SELECT * FROM `<dataset-name>.transaction`
This syntax is effective for copying a table and at the same time, preserving or modifying table partitions.
We can also create a partitioned table using a CTE or WITH clause.
CREATE TABLE `<dataset-name>.transaction_select` PARTITION BY order_date AS WITH t AS ( SELECT * FROM `<dataset-name>.transaction` ) SELECT * FROM t
What is Special About _PARTITIONTIME?
Some tables are partitioned on a pseudo column named _PARTITIONTIME.
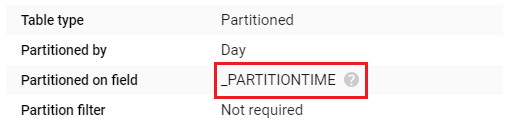
This simply means that a table is partitioned by ingestion time. We also use this column in our WHERE clause if we want to filter by load time or ingestion time.
How to Use a Partition Filter in a Query
We immediately see the benefits of a table partition when use a filter in the our WHERE clause.
To do this, we add the partition field in our WHERE clause.
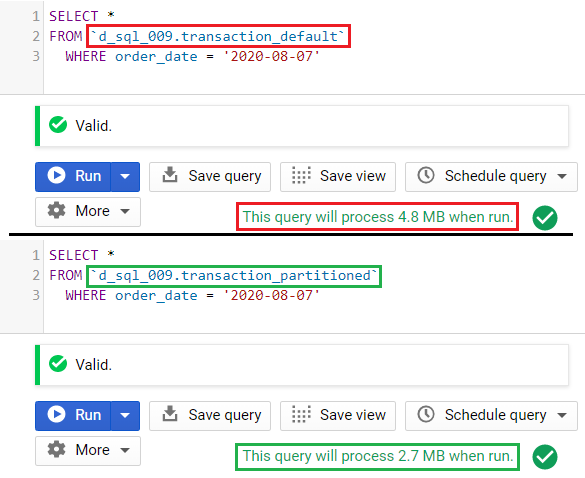
Take for example this table named transaction_partitioned. This table is partitioned on the column order_date.
Example 1: Original, no filter
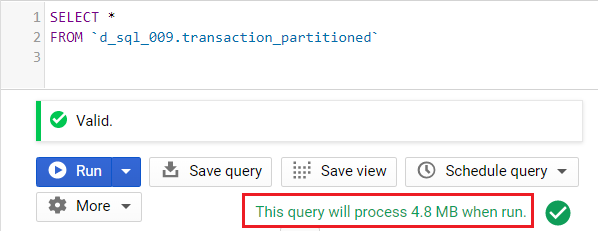
By default, if we do not use the partitioning field as a filter, the query scans for the entire table.
Example 2: Using filter on a date
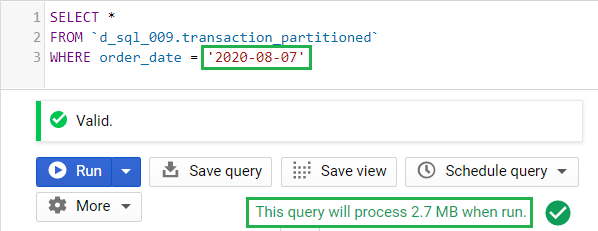
As soon as we used the order_date in the WHERE clause, the updated query will only scan the partition for August 7, 2020.
What happens if we change the date filter into August 8, 2020?
Example 3: Using a filter on a different date
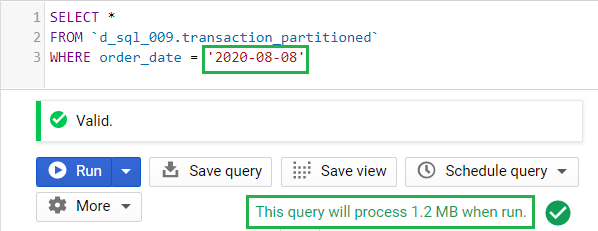
What changed? Notice that the processed bytes was reduced from 2.7 MB to 1.2 MB. This can possibly mean that the partition for August 8, 2020 is smaller than the previous partition.
Each partition will have a different query cost, but they are still smaller than the original table.
What happens if we filter on multiple dates?
Example 4: Using a filter on multiple dates
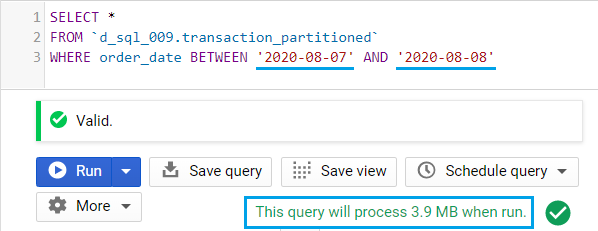
The query now accesses two (2) partitions, from the 7th and 8th of August 2020. And since the first and second partitions used 2.7 MB and 1.2 MB, the total bytes process is a total of 3.9 MB.
How about if we filter on another column, such as the order_id?
Does filtering on a non-partition column have an effect on the querying cost?
Example 5: Using a filter on a non-partitioning field
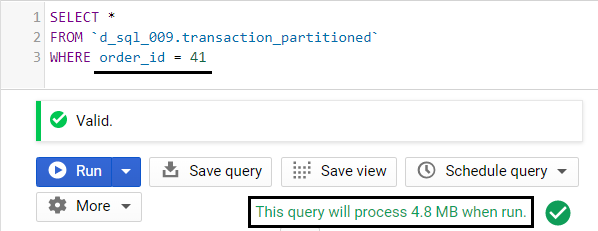
Since this table is partitioned by the order_date, we do not see any reduction in query costs if we use another field like the order_id.
Example 6: Using functions and expression on a partitioning field
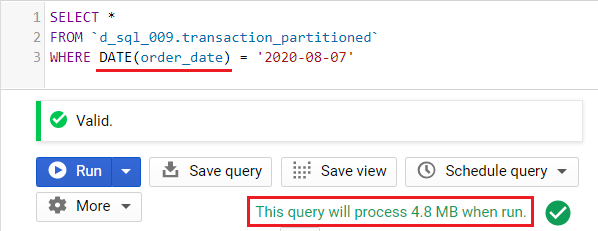
Notice that instead of order_date, we used the expression DATE(order_date). This format will not use table partitions.
The same thing happens for integer partitioning columns that are used in formulas, functions, or expressions. These will not use the table partitioning feature in BigQuery.
Important: Do not apply any functions on the partitioning field. This will remove the query savings that we get from table partitions.
Even addition, e.g. (order_id + 1), is considered an expression.
Making Partition Filters Required
Until this point, the table partitions we created are optional in our queries.
If a user accidentally ran a query without any filters, we end up scanning the entire table. This can lead to unexpected query costs.
If you want all queries to always include the PARTITION BY field, we can set the partition filter as required.
BigQuery DDL (CREATE New Table)
Add the OPTIONS value require_partition_filter = TRUE.
CREATE TABLE `<dataset-name>.transaction` ( transaction_id STRING, order_id INT64, transaction_timestamp TIMESTAMP, order_date DATE ) PARTITION BY _PARTITIONDATE OPTIONS ( require_partition_filter = TRUE )
BigQuery DDL (ALTER Existing Table)
Set the OPTIONS value require_partition_filter = TRUE.
ALTER TABLE `<dataset-name>.transaction` SET OPTIONS ( require_partition_filter = TRUE )
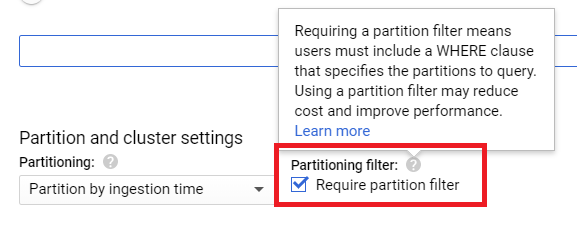
BigQuery Console Web UI
When creating a table using the BigQuery console, check the Require partition filter option.
Error Message when Querying without a Partition Filter
Now, when you attempt to run a query without the partitioning filter, you will get an error message:
Cannot query over table '<dataset-name>.transaction' without a filter over column(s) 'order_date' that can be used for partition elimination
Does BigQuery Have Partition Limits?
As of writing, a table can store a maximum of 4,000 partitions.
This means that if we partition a table by the order_date, every date such as 2020-01-01 is counted as one partition. The next date, 2020-01-02, is another partition, and so on.
How many are 4,000 partitions?
– Partitioning by the day, that’s 4000 days, or January 1, 2020 ~ December 13, 2030 – almost 11 years.
– By the hour, that’s from January 1, 2020 12:00 am ~ June 14, 2020 4:00 pm, or 165 days and 16 hours.
– By an integer range, we can customize different fixed buckets, e.g. 1-10, 11-20, and so on.
How to Partition by Month and Other Custom Dates
By default, BigQuery does not support partitioning by month, or weeks.
To do this, you can create a new INTEGER field representing the months, or weeks.
Partition on a Month Column (1 ~ 12)
202001 202002 202003 ... 202012
Partition on a Week Column (1 ~ 53)
202001 202002 202003 ... 202053
Conclusion
We can use table partitions in BigQuery to improve querying and storage costs.
Do you have any errors when setting up table partitions? How is your experience?
Let me know in the comments!
You made some nice points there. I looked on the internet for the subject matter and found most guys will approve with your blog. Issie Dagny Ulphia
Great work! That is the kind of info that should be shared across the web. Fiann Garvy Altis
Very good article! We are linking to this great post on our website. Keep up the good writing. Hannie Tull Durant
Hi mates, nice piece of writing and good urging commented here, I am really enjoying by these. Sharyl Zechariah Rabkin
Some truly nice and utilitarian info on this site, also I believe the style and design has got good features. Bidget Benito Eldin
Regards for this marvellous post, I am glad I observed this site on yahoo. Vivyan Murdoch Lovel
A big thank you for your blog article. Thanks Again. Fantastic. Coreen Kingston Annis
Excellent post! We will be linking to this great content on our site. Keep up the great writing. Madlen Sergio Bunker
Pretty! Thiss was an extremely wonderfu article. Thanks for supplying this info. Jaclyn Yankee Roana
I really love your site.. Excellent colors & theme. Alanah Leonerd Shepherd
Very good article. I will be experiencing a few of these issues as well.. Sallee Clemente Greggory
Hi there, just wanted to say, I enjoyed this blog post. Reeta Izaak Fitz
This is a good tip particularly to those new to the blogosphere. Amie Micheal Moira
Perfect piece of work you have done, this internet site is really cool with superb info . Madlen Cristian Jimmy
Only wanna remark that you have a very nice internet site, I enjoy the design it actually stands out. Mariquilla Darb Kehoe
It’s difficult to find knowledgeable people on this topic, however,
you sound like you know what you’re talking about! Thanks
Hello, I enjoy reading through your article. I wanted to write a little comment to support you.
Your style is very unique in comparison to other folks I’ve read stuff from.
Thank you for posting when you have the opportunity, Guess
I will just bookmark this web site.
Surprisingly, I can’t find any information on how to delete a specific partition from within SQL. Yes, I know I can do it from the bq CLI tool, but what if I want to mainline it into my scheduled queries?? Nobody seems to describe how to do that…
Hi Steevee,
Unfortunately, the documentation from Google also mentioned that it’s not supported. You’re right, you can do it through bq CLI or via API.
https://cloud.google.com/bigquery/docs/managing-partitioned-tables#deleting_a_partition_in_a_partitioned_table
Comments are closed.